
Die europäische Datenschutz-Organisation Noyb hat in neun EU-Ländern Beschwerden gegen die von Elon Musk geführte Online-Plattform X eingereicht. Nach Angaben der Initiative wurde in Belgien, Frankreich, Griechenland, Irland, Italien, den Niederlanden, Österreich, Polen und Spanien ein „Dringlichkeitsverfahren“ gemäß Artikel 66 DSGVO beantragt.
Anlass war die unangekündigte Verwendung von Nutzerdaten für das Training des LLM, auf denen der X-Chatbots Grok basiert. Nachdem die irische Datenschutzbehörde DPC zuvor nach Ansicht von Noyb nicht ausreichend durchgegriffen habe, hat die Organisation letztlich Beschwerde erhoben.
Auch Meta wollte 2024 die europäischen Nutzerdaten für das Training seines LLM verwenden, doch sie taten es wenigstens mit Ankündigung und einem möglichen Widerspruchsverfahren (das bei mir wiederholt nicht funktioniert hat).
Was bedeutet die „Dringlichkeit“?
Dringlichkeit für die Beschwerde ist angeraten, weil X bereits mit der Verarbeitung der Daten begonnen hat. Bei einer Dringlichkeit dürfen Datenschutzbehörden vorläufige Anordnungen treffen. Dreist war in diesem Zusammenhang seitens X, dass ein Zustimmungshäkchen für das KI-Training in den Benutzereinstellungen automatisch aktiviert wurde.
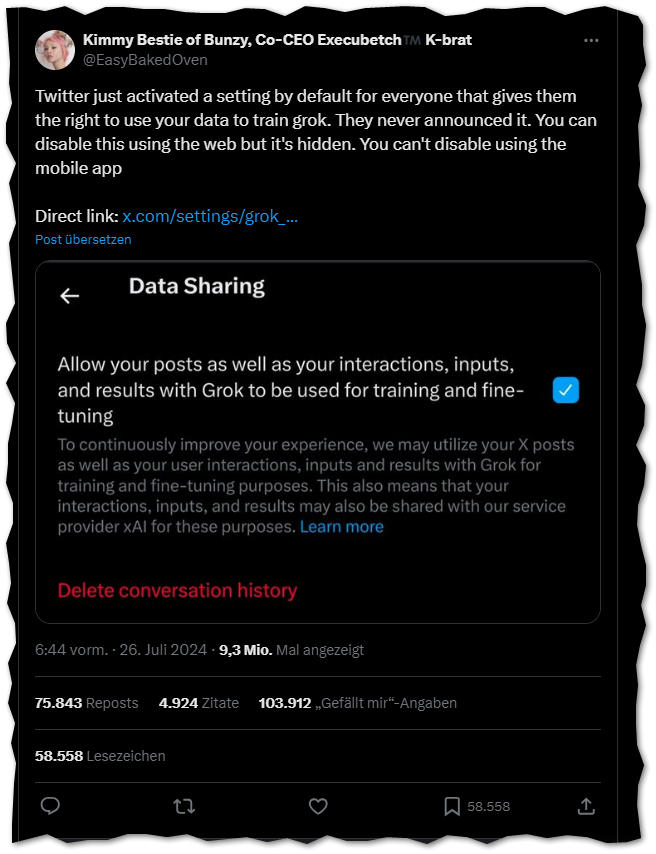
Nach Ansicht des Noyb-Vorstandsvorsitzenden Maximilian Schrems sollten Unternehmen ihren Anwendern eine ganz einfache und leicht verständliche Ja/Nein-Abfrage zur Datenverwendung stellen. Warten wir mit Spannung ab, was die Verfahren auf EU-Ebene bringen.
Die Vorkommnisse zeigen, dass sich die Tech-Riesen bei ihrer Gier nach originalen menschlichen Trainingsdaten nicht zu fein sind, Datenschutz- und Persönlichkeitsrechte einfach zu übergehen. Gerade soziale Netzwerke mit ihrer unendlichen Fülle an neuem Inhalt scheinen beliebte Datenquellen zu sein. Allerdings befinden sich in diesen Netzwerken auch viele gefälschte Daten, Desinformationen und KI-generierte Inhalte. Nicht einmal bei Bildern kann man sich noch sicher sein, ob sie überhaupt authentisch sind. Ob derartig vermüllte Trainingsdaten tatsächlich hilfreich zur Erstellung hochwertiger LLMs sind, darf bezweifelt werden.